|
I'm a research scientist at Google DeepMind in San Francisco, where I work on NeRF-related research and other problems at the intersection of computer vision, graphics, and machine learning. I received my PhD from the EECS Department at UC Berkeley in 2020, where I was advised by Ren Ng and Ravi Ramamoorthi. During my PhD, I interned twice at Google Research, hosted by Jon Barron in Mountain View and Noah Snavely in New York. I graduated from Duke University in 2014, where I worked with Sina Farsiu on research problems in medical computer vision. I've been fortunate to receive the 2025 SIGGRAPH Significant New Researcher Award, the 2021 ACM Doctoral Disseration Award Honorable Mention, the 2020 David J. Sakrison Memorial Prize, and best paper awards at ECCV 2020, ICCV 2021, and CVPR 2022. |

|
Research and Publications |

|
ROGR: Relightable 3D Objects using Generative Relighting
Jiapeng Tang*, Matthew J. Levine*, Dor Verbin, Stephan J. Garbin, Matthias Nießner, Ricardo Martin Brualla, Pratul Srinivasan, Philipp Henzler NeurIPS, 2025 (Spotlight) project page / arXiv We use a multi-view relighting model to build a lighting-conditioned NeRF that generalizes to unseen lighting and doesn't require per-lighting optimization |
|
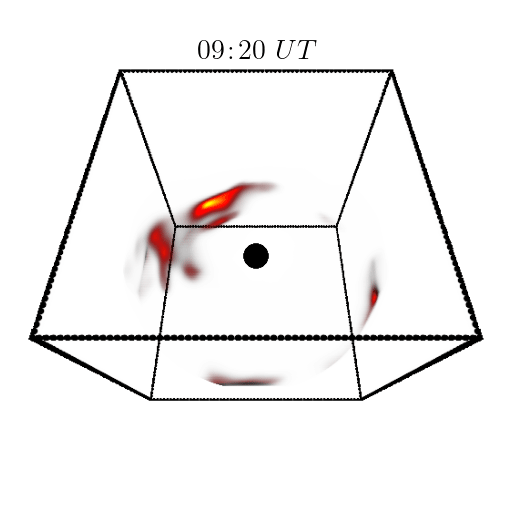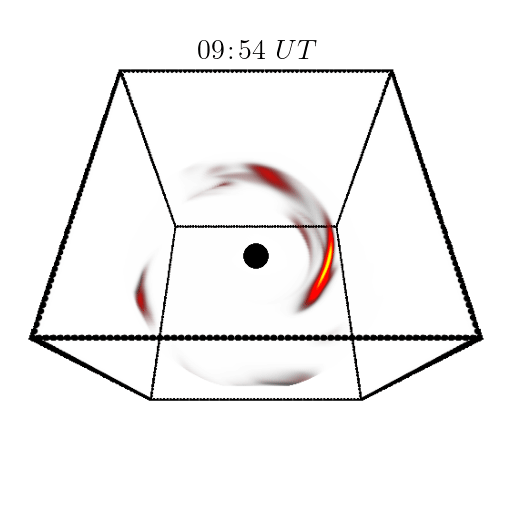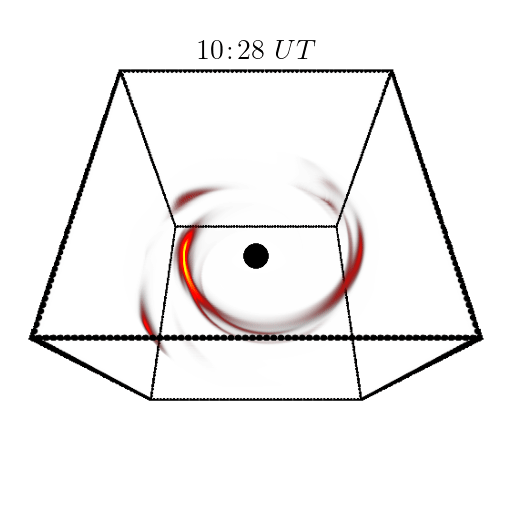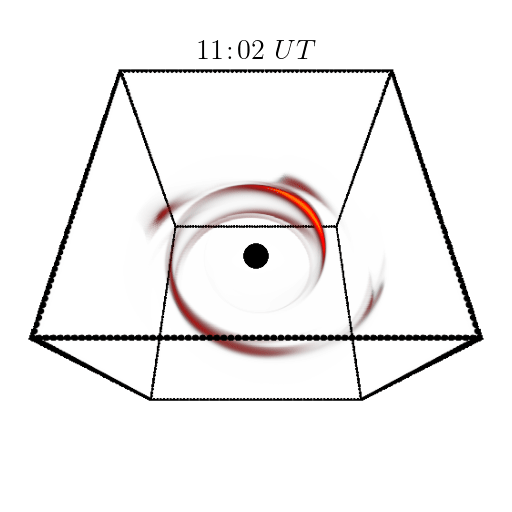
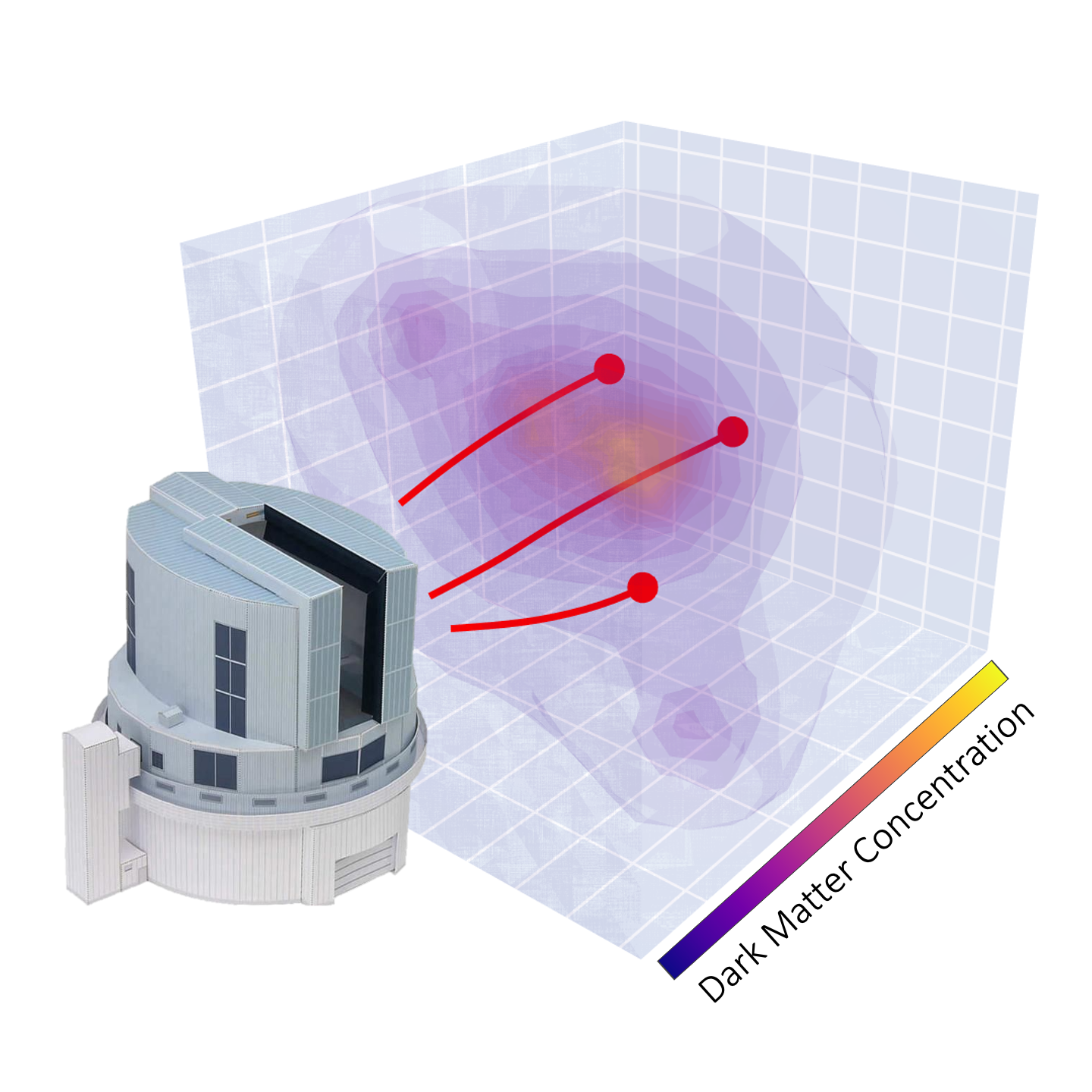
Orbital polarimetric tomography of a flare near the Sagittarius A* supermassive black hole
Aviad Levis, Andrew A. Chael, Katherine L. Bouman, Maciek Wielgus, Pratul Srinivasan Nature Astronomy project page / arXiv / code First 3D reconstruction of the high-energy gas "flares" rotating around a black hole. |

|
Bolt3D: Generating 3D Scenes in Seconds
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T. Barron, Philipp Henzler ICCV, 2025 project page / arXiv By training a latent diffusion model to directly output 3D Gaussians we enable fast (~6 seconds on a single GPU) feed-forward 3D scene generation. |
|
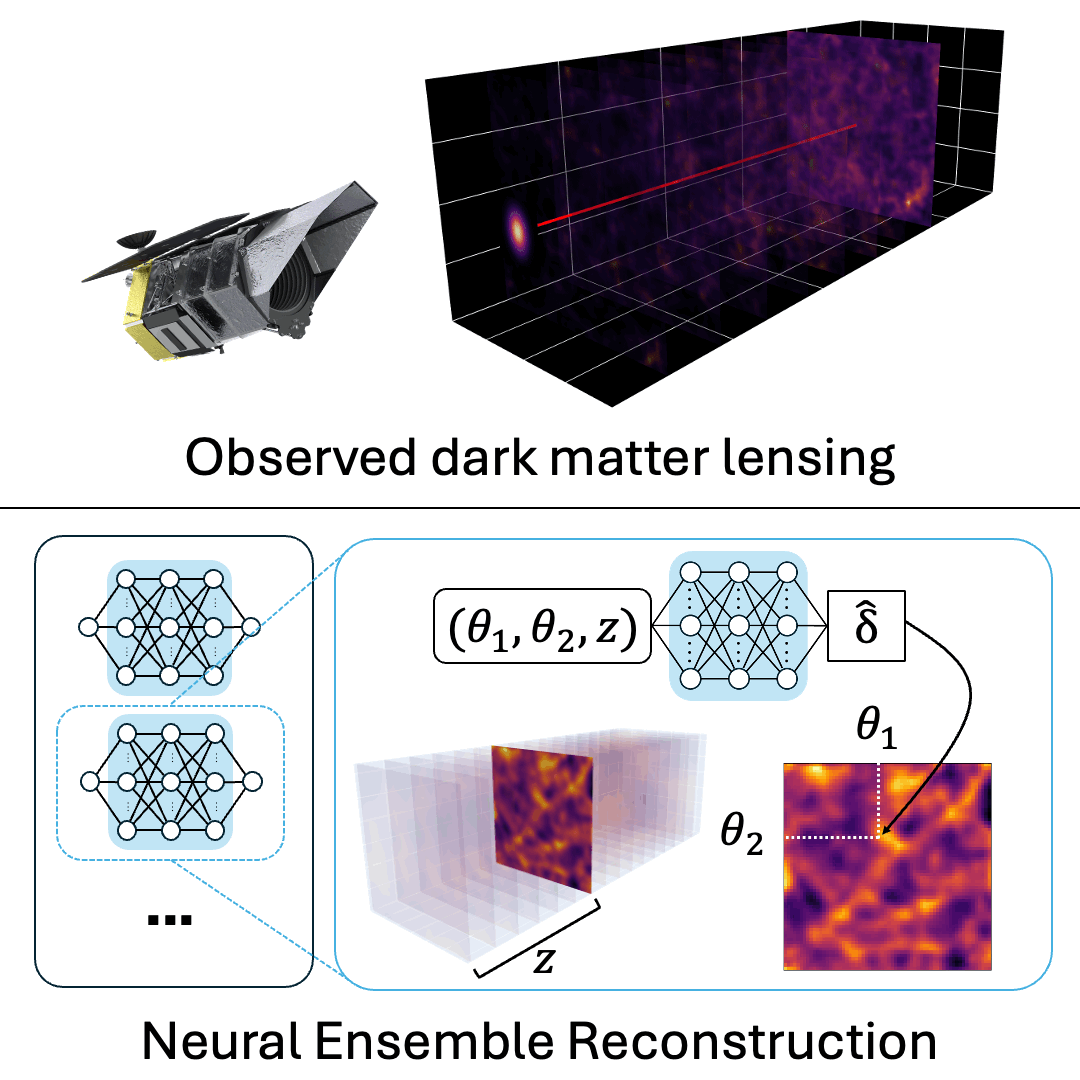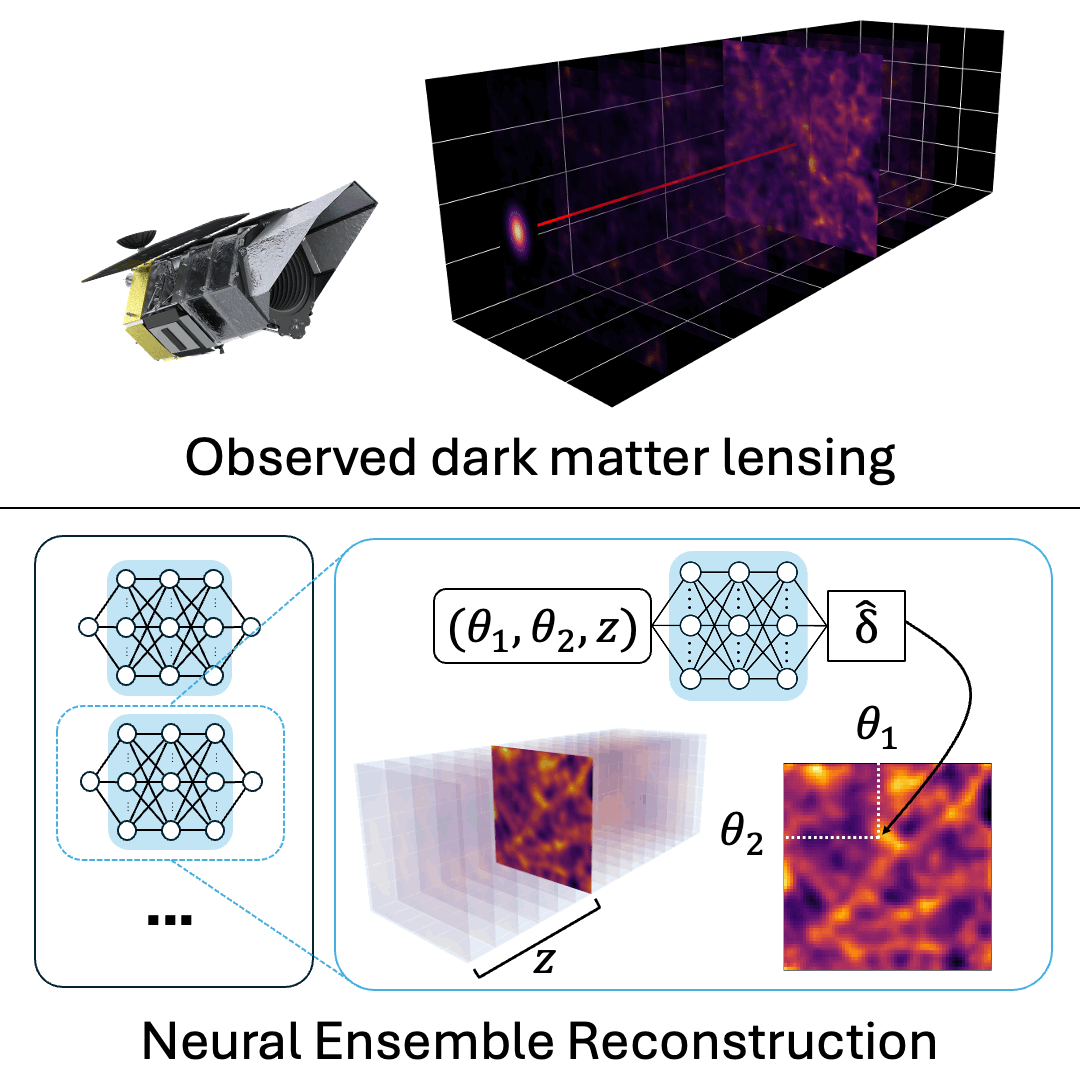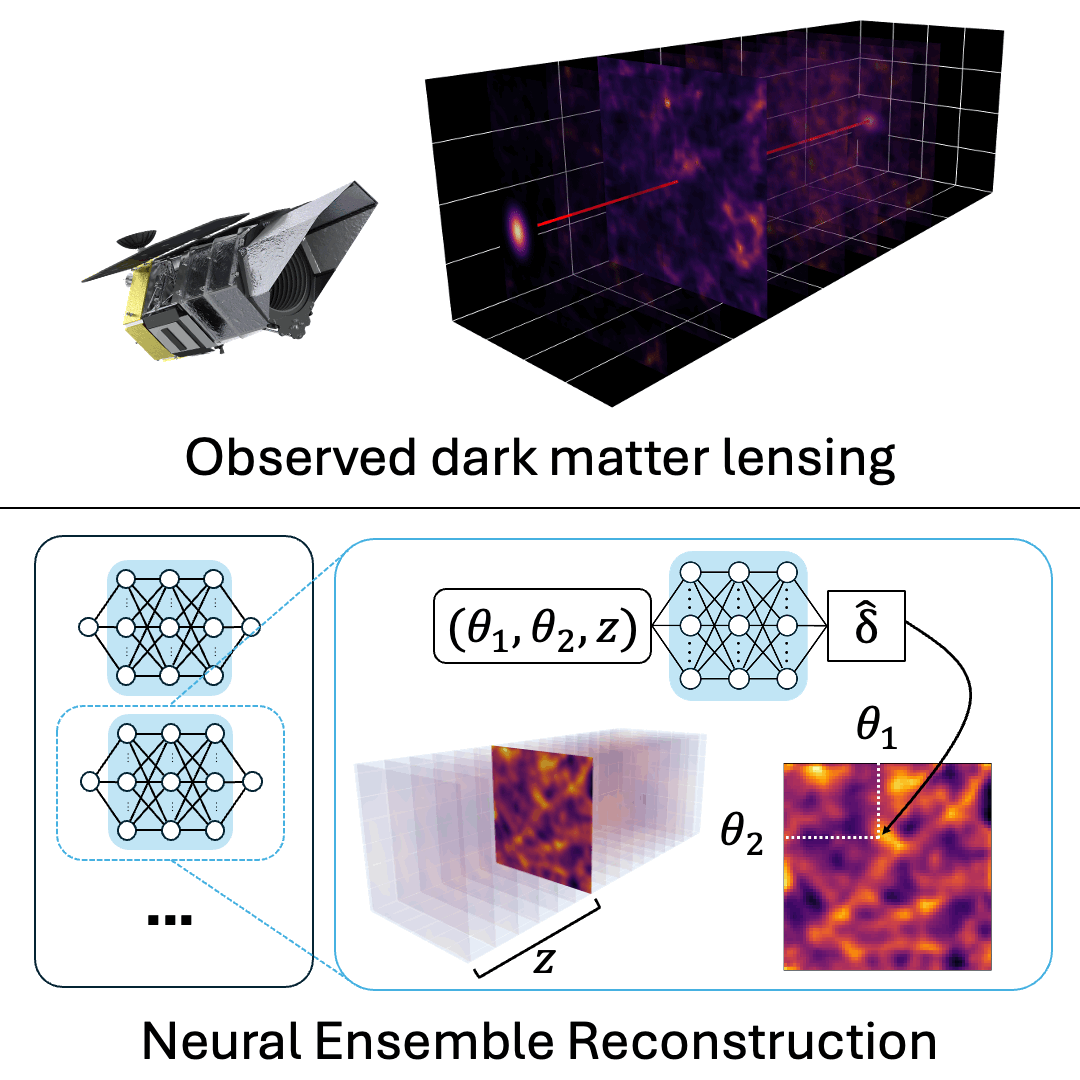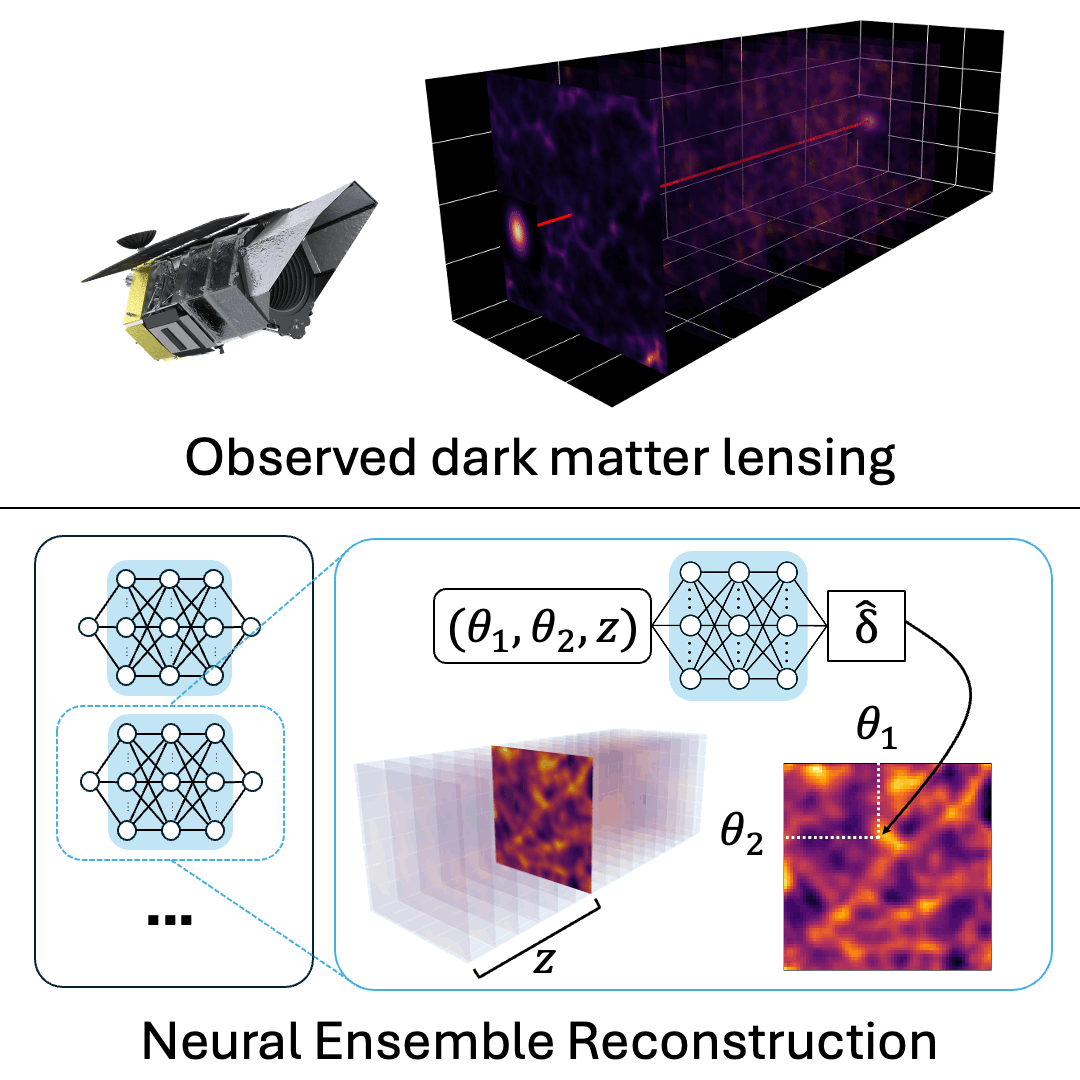
Revealing the 3D Cosmic Web through Gravitationally Constrained Neural Fields
Brandon Zhao, Aviad Levis, Liam Connor, Pratul Srinivasan, Katherine L. Bouman ICLR, 2025 project page / arXiv / code We reconstruct 3D dark matter fields by optimizing a neural field ensemble through a differentiable simulation of weak gravitational lensing. |

|
Generative Multiview Relighting for 3D Reconstruction under Extreme Illumination Variation
Hadi Alzayer, Philipp Henzler, Jonathan T. Barron, Jia-Bin Huang, Pratul P. Srinivasan, Dor Verbin CVPR, 2025 (Highlight) project page / arXiv Images taken under extreme illumination variation can be made consistent with diffusion, and this enables high-quality 3D reconstruction. |

|
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Alex Trevithick, Roni Paiss, Philipp Henzler, Dor Verbin, Rundi Wu, Hadi Alzayer, Ruiqi Gao, Ben Poole, Jonathan T. Barron, Aleksander Holynski, Ravi Ramamoorthi, Pratul P. Srinivasan CVPR, 2025 project page / arXiv Simulating the world with video models lets you make inconsistent captures consistent. |

|
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
Dor Verbin, Pratul Srinivasan, Peter Hedman, Benjamin Attal, Ben Mildenhall, Richard Szeliski, Jonathan T. Barron SIGGRAPH Asia, 2024 project page / arXiv Casting reflection cones inside NeRF lets us synthesize photorealistic specular appearance in real-world scenes. |

|
IllumiNeRF: 3D Relighting without Inverse Rendering
Xiaoming Zhao, Pratul Srinivasan, Dor Verbin, Keunhong Park, Ricardo Martin Brualla, Philipp Henzler NeurIPS, 2024 project page / arXiv 3D relighting by distilling samples from a 2D image relighting diffusion model into a latent-variable NeRF. |

|
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao*, Aleksander Holynski*, Philipp Henzler, Arthur Brussee, Ricardo Martin Brualla, Pratul Srinivasan, Jonathan T. Barron, Ben Poole* NeurIPS, 2024 (Oral Presentation) project page / arXiv A system built around diffusion and NeRF that does text-to-3D, image-to-3D, and few-view reconstruction, trains in 1 minute, and renders at 60FPS in a browser. |

|
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Benjamin Attal, Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Matthew O'Toole, Pratul Srinivasan ECCV, 2024 (Oral Presentation) project page / arXiv Using radiance caches, importance sampling, and control variates helps reduce bias in inverse rendering, resulting in better estimates of geometry, materials, and lighting. |

|
Nuvo: Neural UV Mapping for Unruly 3D Representations
Pratul Srinivasan, Stephan J. Garbin, Dor Verbin, Jonathan T. Barron, Ben Mildenhall ECCV, 2024 project page / video / arXiv We use neural fields to recover editable UV mappings for challenging geometry (e.g. NeRFs, marching cubes meshes, DreamFusion). |

|
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Christian Reiser, Stephan J. Garbin, Pratul Srinivasan, Dor Verbin, Richard Szeliski, Ben Mildenhall, Jonathan T. Barron, Peter Hedman*, Andreas Geiger* SIGGRAPH, 2024 project page / video / arXiv Applying anti-aliasing to a discrete opacity grid lets you render a hard representation into a soft image, and this enables highly-detailed mesh recovery. |
|
Single-View Refractive Index Tomography with Neural Fields
Brandon Zhao, Aviad Levis, Liam Connor, Pratul Srinivasan, Katherine L. Bouman CVPR, 2024 project page / code / arXiv We reconstruct a 3D refractive field from a single image by modeling how rays curve through a volume with known light sources, to reconstruct dark matter distributions (in simulation). |

|
Eclipse: Disambiguating Illumination and Materials using Unintended Shadows
Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Todd Zickler, Pratul Srinivasan CVPR, 2024 (Oral Presentation) project page / video / arXiv Shadows cast by unobserved occluders provide a high-frequency cue for recovering illumination and materials. |

|
ReconFusion: 3D Reconstruction with Diffusion Priors
Rundi Wu*, Ben Mildenhall*, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, Aleksander Holynski* CVPR, 2024 project page / arXiv Using a multi-image diffusion model as a regularizer lets you recover high-quality radiance fields from just a handful of images. |

|
Generative Powers of Ten
Xiaojuan Wang, Janne Kontkanen, Brian Curless, Steve Seitz, Ira Kemelmacher, Ben Mildenhall, Pratul Srinivasan, Dor Verbin, Aleksander Holynski CVPR, 2024 project page / arXiv Use a text-to-image model to generate consistent content across drastically varying scales. |

|
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman ICCV, 2023 (Oral Presentation, Best Paper Finalist) project page / video / arXiv Combining mip-NeRF 360 and Instant NGP lets us reconstruct huge scenes. |

|
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Lior Yariv*, Peter Hedman*, Christian Reiser, Dor Verbin, Pratul Srinivasan, Richard Szeliski, Jonathan T. Barron, Ben Mildenhall SIGGRAPH, 2023 project page / video / arXiv Use SDFs to bake a NeRF-like model into a high quality mesh and do real-time view synthesis. |
|
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Christian Reiser, Richard Szeliski, Dor Verbin, Pratul Srinivasan, Ben Mildenhall, Andreas Geiger, Jonathan T. Barron, Peter Hedman SIGGRAPH, 2023 project page / video / arXiv Use volumetric rendering with a sparse 3D feature grid and 2D feature planes to do real-time view synthesis. |


|
VQ3D: Learning a 3D Generative Model on ImageNet
Kyle Sargent, Jing Yu Koh, Han Zhang, Huiwen Chang, Charles Herrmann, Pratul Srinivasan, Jiajun Wu, Deqing Sun CVPR, 2023 (Oral Presentation, Best Paper Finalist) project page / arXiv / ViT-VQGAN plus a NeRF-based decoder that enables both single-image view synthesis and 3D generation. |

|
PersonNeRF: Personalized Reconstruction from Photo Collections
Chung-Yi Weng, Pratul Srinivasan, Brian Curless, Ira Kemelmacher-Shlizerman CVPR, 2023 project page / arXiv / video Construct a personalized 3D model from an unstructed photo collection. |

|
Gravitationally Lensed Black Hole Emission Tomography
Aviad Levis*, Pratul Srinivasan*, Andrew A. Chael, Ren Ng, Katherine L. Bouman CVPR, 2022 project page / arXiv / video NeRF for the problem of reconstructing the dynamic emissive volume around a black hole. |

|
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, Pratul Srinivasan CVPR, 2022 (Oral Presentation, Best Student Paper Honorable Mention) project page / arXiv / video We fix NeRF's shortcomings when representing shiny materials, greatly improve NeRF's normal vectors, and enable intuitive material editing. |

|
Block-NeRF: Scalable Large Scene Neural View Synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul Srinivasan, Jonathan T. Barron, Henrik Kretzschmar CVPR, 2022 (Oral Presentation) project page / arXiv / video We build city-scale scenes from many NeRFs, trained using millions of images. |

|
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
Chung-Yi Weng, Brian Curless, Pratul Srinivasan, Jonathan T. Barron, Ira Kemelmacher-Shlizerman CVPR, 2022 (Oral Presentation) project page / arXiv / video Free-viewpoint rendering of any body pose from a monocular video of a human. |

|
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Ben Mildenhall, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron CVPR, 2022 (Oral Presentation) project page / arXiv / video We train NeRFs directly on linear raw camera images, enabling new HDR view synthesis applications and greatly increasing robustness to camera noise. |

|
Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman CVPR, 2022 (Oral Presentation) project page / arXiv / video We extend mip-NeRF to produce photorealistic results on unbounded scenes. |

|
Urban Radiance Fields
Konstantinos Rematas, Andrew Liu, Pratul Srinivasan, Jonathan T. Barron, Andrea Tagliasacchi, Tom Funkhouser, Vittorio Ferrari CVPR, 2022 project page / arXiv / video We incorporate lidar data and explicitly model the sky to reconstruct urban environments with NeRF. |
 
|
Dense Depth Priors for Neural Radiance Fields from Sparse Input Views
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul Srinivasan, Matthias Nießner CVPR, 2022 project page / arXiv / video We apply dense depth completion techniques to freely-available sparse stereo data to guide NeRF reconstructions from few input images. |
 
|
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
Xiuming Zhang, Pratul Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, Jonathan T. Barron ACM Transactions on Graphics (SIGGRAPH Asia), 2021 project page / video / arXiv We recover relightable NeRF-like models from images under a single unknown lighting condition. |
|
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan ICCV, 2021 (Oral Presentation, Best Paper Honorable Mention) project page / arXiv / video We modify NeRF to output volume density and emitted radiance at a volume of space instead of a single point to fix NeRF's issues with sampling and aliasing. |

|
Baking Neural Radiance Fields for Real-Time View Synthesis
Peter Hedman, Pratul Srinivasan , Ben Mildenhall, Jonathan T. Barron, Paul Debevec ICCV, 2021 (Oral Presentation) project page / arXiv / video / demo We "bake" a trained NeRF into a sparse voxel grid of colors and features in order to render it in real-time. |
 
|
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Shumian Xin, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul Srinivasan, Jiawen Chen, Ioannis Gkioulekas, Rahul Garg ICCV, 2021 (Oral Presentation) project page / code / arXiv We deblur dual-pixel images by representing the scene as a multiplane image and carefully considering dual-pixel optics in an optimization framework. |
 
|
NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis
Pratul Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, Jonathan T. Barron CVPR, 2021 project page / video / arXiv We recover relightable NeRF-like models using neural approximations of expensive visibility integrals, so we can simulate complex volumetric light transport during training. |

|
Learned Initializations for Optimizing Coordinate-Based Neural Representations
Matthew Tancik*, Ben Mildenhall*, Terrance Wang, Divi Schmidt, Pratul Srinivasan, Jonathan T. Barron, Ren Ng CVPR, 2021 (Oral Presentation) project page / video / arXiv We use meta-learning to find weight initializations for coordinate-based MLPs that allow them to converge faster and generalize better. |

|
IBRNet: Learning Multi-View Image-Based Rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, Thomas Funkhouser CVPR, 2021 project page / arXiv Training a network that blends source views using a NeRF-like continuous neural volumetric representation, for NeRF-like performance without per-scene training. |
 
|
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
Matthew Tancik*, Pratul Srinivasan*, Ben Mildenhall*, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, Ren Ng NeurIPS, 2020 (Spotlight Presentation) project page / arXiv / code Mapping input coordinates with simple Fourier features before passing them to a fully-connected network enables the network to learn much higher-frequency functions. |

|
Neural Reflectance Fields for Appearance Acquisition
Sai Bi*, Zexiang Xu*, Pratul Srinivasan, Ben Mildenhall, Kalyan Sunkavalli, Milos Hasan, Yannick Hold-Geoffroy, David Kriegman, Ravi Ramamoorthi arXiv, 2020 arXiv We recover relightable NeRF-like models by predicting per-location BRDFs and surface normals, and marching light rays through the NeRF volume to compute visibility. |
|
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Ben Mildenhall*, Pratul Srinivasan*, Matthew Tancik*, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng European Conference on Computer Vision (ECCV), 2020 (Oral Presentation, Best Paper Honorable Mention) project page / arXiv / video / technical overview / code / two minute papers We optimize a simple neural network to represent a scene as a 5D function (3D volume + 2D view direction) from just a set of images, and synthesize photorealistic novel views. |

|
Deep Multi Depth Panoramas for View Synthesis
Kai-En Lin, Zexiang Xu, Ben Mildenhall, Pratul Srinivasan, Yannick Hold-Geoffroy, Stephen DiVerdi, Qi Sun, Kalyan Sunkavalli, Ravi Ramamoorthi European Conference on Computer Vision (ECCV), 2020 arXiv / video We represent scenes as multi-layer panoramas with depth for VR view synthesis. |
|
Lighthouse: Predicting Lighting Volumes for Spatially-Coherent Illumination
Pratul Srinivasan*, Ben Mildenhall*, Matthew Tancik, Jonathan T. Barron, Richard Tucker, Noah Snavely Computer Vision and Pattern Recognition (CVPR), 2020 project page / arXiv / video / code We predict a multiscale light volume from an input stereo pair, and render this volume to compute illumination at any 3D point for relighting inserted virtual objects. |
 
|
Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines
Ben Mildenhall*, Pratul Srinivasan*, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar SIGGRAPH, 2019 project page / arXiv / video / code We develop a deep learning method for rendering novel views of complex real world scenes from a small number of images, and analyze it with light field sampling theory. |
 
|
Pushing the Boundaries of View Extrapolation with Multiplane Images
Pratul Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, Noah Snavely Computer Vision and Pattern Recognition (CVPR), 2019 (Oral Presentation, Best Paper Award Finalist) arXiv / video / code We use Fourier theory to show the limits of view extrapolation with multiplane images, and develop a deep learning pipeline with 3D inpainting for better view extrapolation results. |
 
|
Aperture Supervision for Monocular Depth Estimation
Pratul Srinivasan, Rahul Garg, Neal Wadhwa, Ren Ng, Jonathan T. Barron Computer Vision and Pattern Recognition (CVPR), 2018 arXiv / code We train a neural network to estimate a depth map from a single image using only images with different-sized apertures as supervision, and use this to synthesize artificial bokeh. |
|
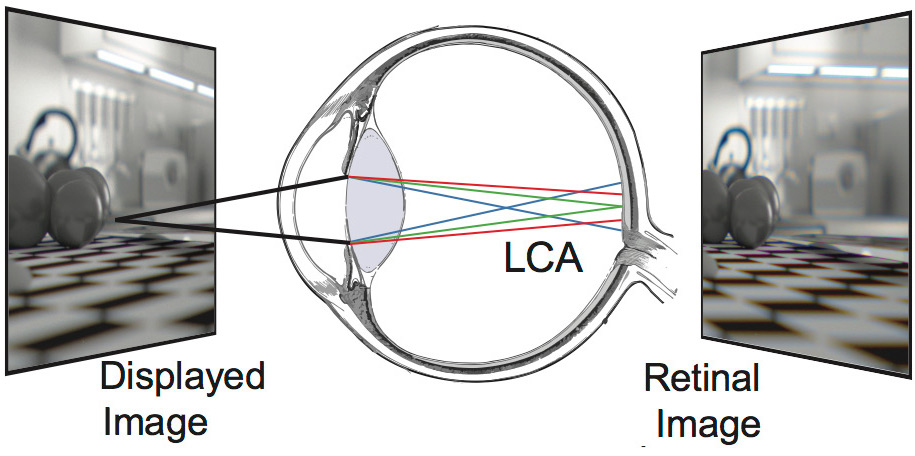
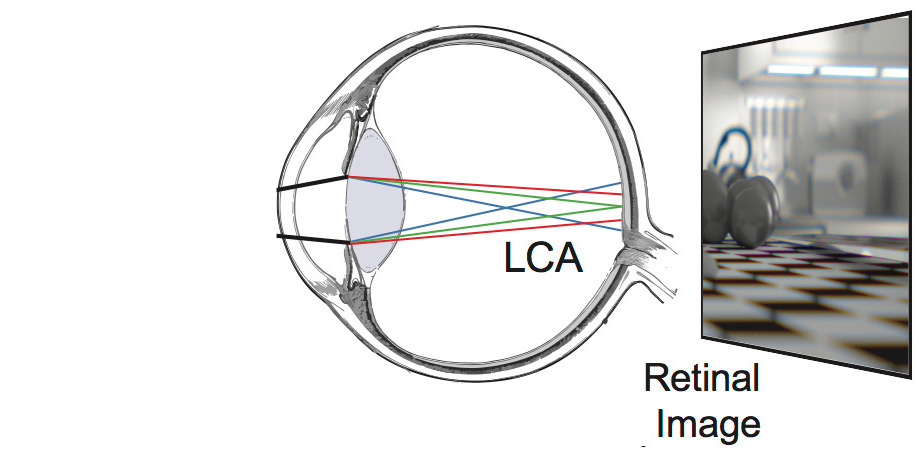
ChromaBlur: Rendering Chromatic Eye Aberration Improves Accommodation and Realism
Steven A. Cholewiak, Gordon D. Love, Pratul Srinivasan, Ren Ng, Martin S. Banks SIGGRAPH Asia, 2017 project page / video We show that properly considering the eye's aberrations when rendering for VR displays increases perceived realism and helps drive accomodation. |
 
|
Learning to Synthesize a 4D RGBD Light Field from a Single Image
Pratul Srinivasan, Tongzhou Wang, Ashwin Sreelal, Ravi Ramamoorthi, Ren Ng International Conference on Computer Vision (ICCV), 2017 (Spotlight Presentation) arXiv / video / code / supplementary PDF We train a neural network to predict ray depths and RGB colors for a local light field around a single input image. |
 
|
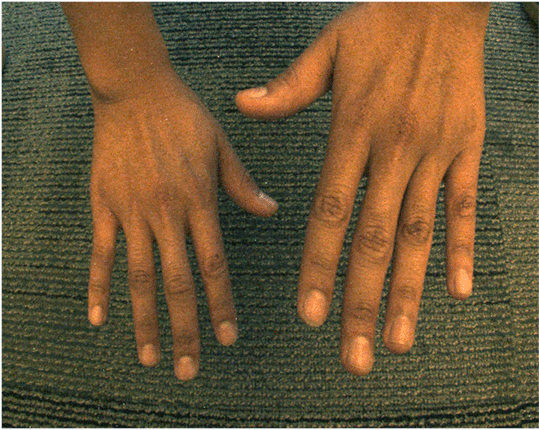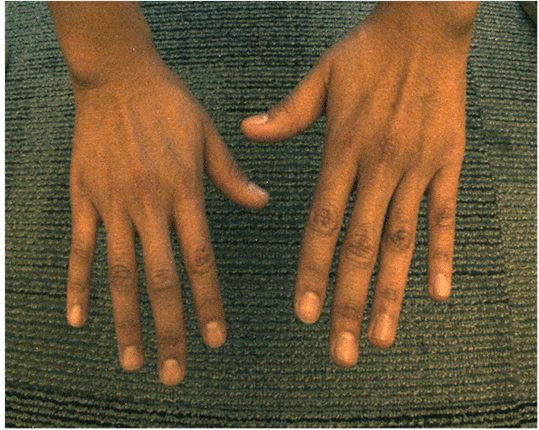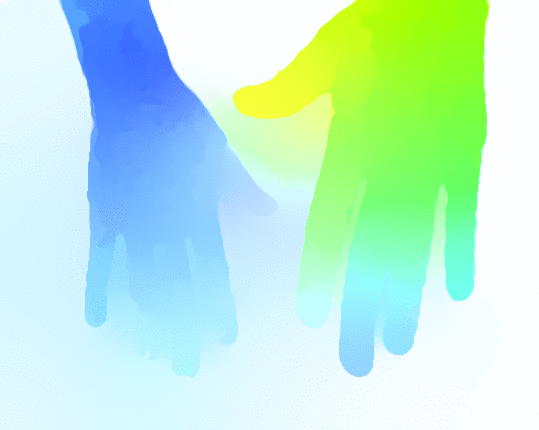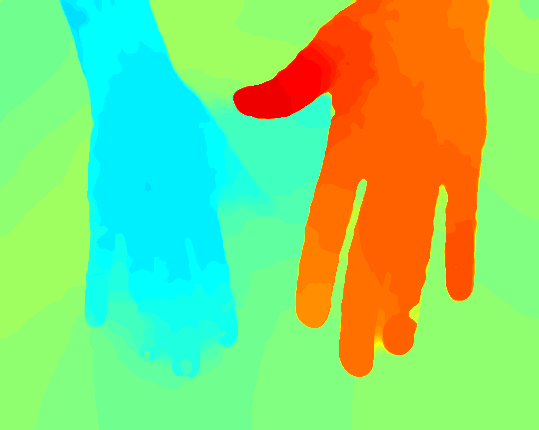
Light Field Blind Motion Deblurring
Pratul Srinivasan, Ren Ng, Ravi Ramamoorthi Conference Computer Vision and Pattern Recognition (CVPR), 2017 (Oral Presentation) arXiv / video / code / additional results We develop Fourier theory to describe the effects of camera motion on light fields, and an optimization algorithm for deblurring light fields captured with unknown camera motion. |
|
Oriented Light-Field Windows for Scene Flow
Pratul Srinivasan, Michael W. Tao, Ren Ng, Ravi Ramamoorthi International Conference on Computer Vision (ICCV), 2015 paper PDF / code / video We develop a 4D light field descriptor and an algorithm to use these to compute scene flow (3D motion of observed points) from two captured light fields. |
|
Shape Estimation from Shading, Defocus, and Correspondence Using Light-Field Angular Coherence
Michael W. Tao, Pratul Srinivasan, Sunil Hadap, Szymon Rusinkiewicz, Jitendra Malik, Ravi Ramamoorthi IEEE Transactions on Pattern Matching and Machine Intelligence (PAMI), 2017 and Conference on Computer Vision and Pattern Recognition (CVPR), 2015 conference PDF / journal PDF / code We develop an algorithm that jointly considers cues from defocus, correspondence, and shading to estimate better depths from a light field. |
|
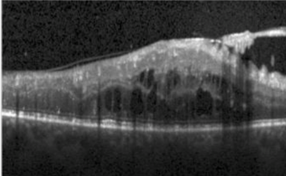
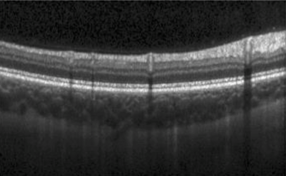
Fully Automated Detection of Diabetic Macular Edema and Dry Age-Related Macular Degeneration from Optical Coherence Tomography Images
Pratul Srinivasan, Leo A. Kim, Priyatham S. Mettu, Scott W. Cousins, Grant M. Comer, Joseph A. Izatt, Sina Farsiu Biomedical Optics Express, 2014 journal article / dataset We develop a classification algorithm to detect diseases from OCT images of the retina. |
|
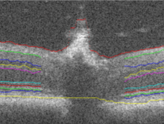
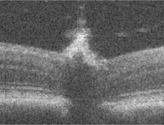
Automatic Segmentation of up to Ten Layer Boundaries in SD-OCT Images of the Mouse Retina With and Without Missing Layers due to Pathology
Pratul Srinivasan, Stephanie J. Heflin, Joseph A. Izatt, Vadim Y. Arshavsky, Sina Farsiu Biomedical Optics Express, 2014 journal article We develop a segmentation algorithm to quantify the shape of retinal layers in OCT images that is robust to deformations due to disease. |
|
You've probably seen this website template before, thanks to Jon Barron. |